Web Scrapping con F#
NOTA: El conenido de este post esta basado en este proyecto
https://github.com/AngelMunoz/Escalin
Cosas simples en FSharp
Hola! esta es la sexta entrada en cosas simples con F#!
Si alguna vez has querido sacar informacion periodicamente de algun sitio web, o quiza eres un QA automation que quiere hacer pruebas E2E (end to end) entonces Playwright puede que sea una opcion para ti, similar a Cypress o PhantomJS. Playwright es una libreria que te permite automatizar interacciones con sitios web.
Playwright ofrece los siguientes navegadores
- Chromium
- Edge
- Chrome
- Firefox
- Webkit
Generalmente estas herramientas estan hechas para javascript (playwright no es la excepcion) pero Playwright ofrece librerias para .NET asi que si eres un desarrollador que gusta de usar F#, VB o C# puedes empezar a hacer web scrapping o pruebas E2E con playwright.
Pre-requisitos
En este post nos vamos a enfocar en F# y .NET asi que necesitas tener el .NET SDK instalado y la herramienta global de playwright
dotnet tool install --global Microsoft.Playwright.CLI
Una vez instalado podemos iniciar con un proyecto de consola de la siguiente manera
# tambien puedes usar VB o C# si asi lo prefieres
dotnet new console -lang F# -o Escalin
En este caso cree un proyecto llamado Escalin una vez creado el proyecto vamos a instalar las siguientes dependencias
cd Escalin
dotnet add package Microsoft.Playwright
dotnet add package Ply
dotnet build
# esta linea es para instalar los navegadores que usara playwright
# si ya los has instalado antes por algun otro medio lo puedes omitir
playwright install
SCRIPTING: Puedes usar playwright con scripts de F# pero es necesario que hayas instalado previamente los navegadores, ya sea que hayas creado un proyecto dummy con los pasos de arriba o usado la herramienta de npm de playwright para hacerlo
Una vez agregadas nuestras dependencias podemos abrir el codigo en vscode con Ionide, Rider o Visual Studio.
Ejercicio
Para el ejercicio de hoy vamos a hacer un web scrapping de mi propio blog y conseguiremos una lista de resumenes de los articulos y los guardaremos en un archivo json.
Para esto necesitaremos:
- Navegar a
https://blog.tunaxor.me - Seleccionar todas las entradas en la pagina principal
- Extraer el texto de cada entrada
- Generar un "Post" a partir de lo que obtengamos
- Escribir en un archivo JSON llamados
posts.json
Primero vamos a agregar los namespaces que necesitamos para trabajar todo lo que vamos a hacer y agregar un par de tipos que nos ayudaran.
open Microsoft.Playwright
// vamos a tener que trabajar de manera asincrona
open System.Threading.Tasks
open FSharp.Control.Tasks
// para escribir el json al disco
open System.IO
// para serializar nuesto modelo "Post" que escribiremos abajo
open System.Text.Json
// declaramos una union (Discriminated Union en ingles)
type Browser =
| Chromium
| Chrome
| Edge
| Firefox
| Webkit
// escribimos una representacion "bonita" de cada miembro de la union
member instancia.AsString =
match instancia with
| Chromium -> "Chromium"
| Chrome -> "Chrome"
| Edge -> "Edge"
| Firefox -> "Firefox"
| Webkit -> "Webkit"
type Post =
{ title: string
author: string
summary: string
tags: string array
date: string }
El objetivo es tener algo como lo siguiete dentro de nuestro main
[<EntryPoint>]
let main _ =
Playwright.CreateAsync()
|> getBrowser Firefox
|> getPage "https://blog.tunaxor.me"
|> getPostSummaries
|> writePostsToFile
|> Async.AwaitTask
|> Async.RunSynchronously
0
Significa que para esto, necesitamos crear las funciones
getBrowser- que tome como parametro nuestro browser y un Task con instancia de playwrightgetPage- que tome como parametro una cadena de textoUrly un Task con una instancia de browsergetPostSummaries- que tome como parametro un Task con una instancia de una paginaWritePostsToFile- que tome como parametro un Task con un arreglo de posts
en el caso de Async.AwaitTask y Async.RunSynchronously no es necesario, por que son implementaciones existentes dentro de F#, tambien haremos uso del operador |> para aplicar el resultado de la funcion anterior, como parametro de la siguiente funcion.
El operador
pipees bastante util y de hecho podria llegar en algun punto a javascriptvisualizado de otra forma podria ser escrito asi
64 |> sumar 10equivale asumar 10 64
Vamos a iniciar entonces con getBrowser
let getBrowser (kind: Browser) (getPlaywright: Task<IPlaywright>) =
task {
// es como si dijeramos
// let playwright = await getPlaywright
let! playwright = getPlaywright
printfn $"Browsing with {kind.AsString}"
/// return! equivale a `return await`
return!
match kind with
| Chromium -> pl.Chromium.LaunchAsync()
| Chrome ->
let opts = BrowserTypeLaunchOptions()
opts.Channel <- "chrome"
pl.Chromium.LaunchAsync(opts)
| Edge ->
let opts = BrowserTypeLaunchOptions()
opts.Channel <- "msedge"
pl.Chromium.LaunchAsync(opts)
| Firefox -> pl.Firefox.LaunchAsync()
| Webkit -> pl.Webkit.LaunchAsync()
}
En este caso, getBrowser es una simple funcion utilitaria que se encarga de proveernos el navegador que nosotros decidamos, es util en caso de que quisieras realizar varias operaciones con diferentes navegadores. en este caso estamos aceptando el task anterior para poder usar el operador |> sin problemas mas adelante, regresamos un Task<IBrowser> en este caso.
Continuamos con la siguiente funcion getPage
let getPage (url: string) (getBrowser: Task<IBrowser>) =
task {
let! browser = getBrowser
printfn $"Navigating to \"{url}\""
// obtenemos una nueva pagina de nuestro navegador
let! page = browser.NewPageAsync()
// navegamos a la url que solicitamos como parametro
let! res = page.GotoAsync url
// nos aseguramos de que si hayamos navegado con exito
if not res.Ok then
// podriamos manejar esta parte mejor, pero por brevedad simplemente
// dejaremos que la funcion falle
return failwith "We couldn't navigate to that page"
return page
}
Esta funcion tambien es algo corta simplemente obtenemos nuestro navegador, abrimos una nueva "pestaña" y navegamos a nuestro sitio que viene en nuestros parametros, al final si nuestra pagina navega exitosamente pues continuamos y regresamos nuestra pagina, de lo contrario fallamos.
La siguiente funcion es getPostSummaries que basicamente se encarga de obtener todos los posts que hay en la pagina que acabamos de visitar en la funcion anterior.
let getPostSummaries (getPage: Task<IPage>) =
task {
let! page = getPage
// la primera parte del scrapping, seleccionamos todos los elementos
// con la clase "card-content"
let! cards = page.QuerySelectorAllAsync(".card-content")
printfn $"Getting Cards from the landing page: {cards.Count}"
return!
cards
// convertimos el IReadOnlyList a un arreglo
|> Seq.toArray
// usamos el modulo `Parallel` para precisamente
// aplicar la funcion // convertElementToPost de manera paralela
|> Array.Parallel.map convertElementToPost
// juntamos todas las operaciones tipo `Task<Post>`
|> Task.WhenAll // regresamos un Task<Post array>
}
Aqui viene lo sabroso! convertElementToPost esta funcion es algo mas complicada pero vamos a definir los pasos internos para tener una idea mas clara de que decidimos hacer aqui.
- dentro del elemento, buscamos el titulo
- dentro del elemento, buscamos el autor
- dentro del elemento, buscamos el contenido
- obtenemos el texto del titulo y el autor
- el contenido lo vamos a separar en un arreglo de partes a partir de que la cadena de texto tenga
... - para el resument trataremos de obtener el primer elemento del arreglo o una cadena vacia de manera predeterminada
- el segundo elemento lo vamos a dividir en un arreglo donde el texto tenga el caracter
\n- Al primer elemento del arreglo lo vamos a dividir nuevamente donde el texto contenga
#para obtener las etiquetas - limpiamos cada etiqueta de espacios extras y filtramos las cadenas vacias
- el segundo elemento le quitamos espacios extra y sera nuestra fecha
- Al primer elemento del arreglo lo vamos a dividir nuevamente donde el texto contenga
todo esto basandonos en que cada entrada tiene mas o menos la siguiente forma de texto:
Simple things in F If you come from PHP, Javascript this might help you understand a... #dotnet #fsharp #mvc #saturn \nJul 16, 2021
let convertElementToPost (element: IElementHandle) =
task {
// paso 1, 2 y 3
let! headerContent = element.QuerySelectorAsync(".title")
let! author = element.QuerySelectorAsync(".subtitle a")
let! content = element.QuerySelectorAsync(".content")
// paso 4
let! title = headerContent.InnerTextAsync()
let! authorText = author.InnerTextAsync()
let! rawContent = content.InnerTextAsync()
// paso 5
let summaryParts = rawContent.Split("...")
let summary =
// paso 6
summaryParts
|> Array.tryHead
|> Option.defaultValue ""
// try to split the tags and the date
let extraParts =
// paso 7
(summaryParts
|> Array.tryLast
// dejamos una cadena con un solo valor, para
// asegurarnos que tendremos al menos un arreglo con dos elementos["", ""]
|> Option.defaultValue "\n")
.Split '\n'
// split the tags given that each has a '#' and trim it, remove it if it's whitespace
let tags =
// paso 7.1
(extraParts
|> Array.tryHead
|> Option.defaultValue "")
.Split('#')
// paso 7.2
|> Array.map (fun s -> s.Trim())
|> Array.filter (System.String.IsNullOrWhiteSpace >> not)
let date =
// paso 7.3
extraParts
|> Array.tryLast
|> Option.defaultValue ""
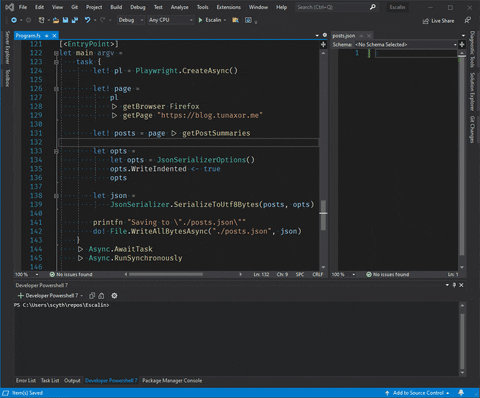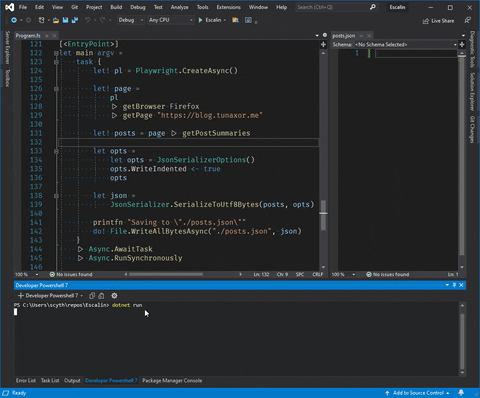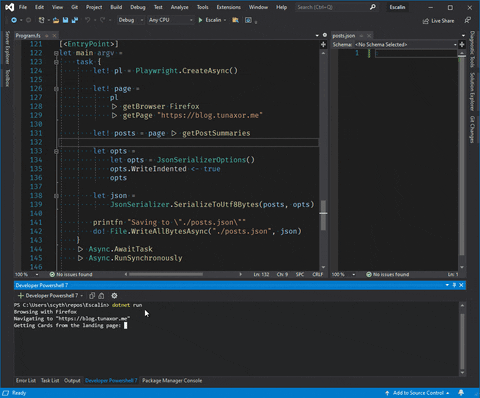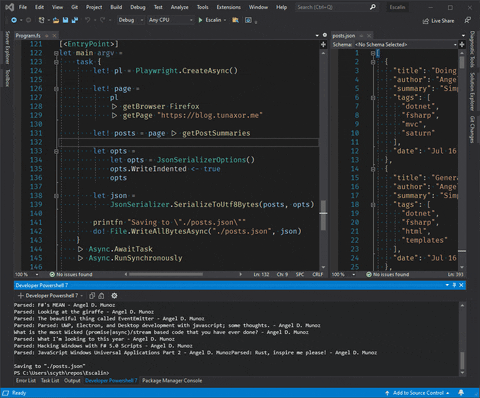
printfn $"Parsed: {title} - {authorText}"
// regresamos el post
return
{ title = title
author = authorText
tags = tags
summary = $"{summary}..."
date = date }
}
Phew! eso estuvo pesado no? manejar cadenas de texto siempre es un lio en mi opinion. Quiza haya formas mas sencillas de hacerlo, pero por el momento fue para lo que dio mi mente.
Continuamos con el ultimo paso writePostsToFile, este es el ultimo paso en nuestra cadena de operaciones y se trata de tomar el arreglo de posts que conseguimos en el paso anterior convertirlo en JSON y escribir el archivo en disco
let writePostsToFile (getPosts: Task<Post array>) =
task {
let! posts = getPosts
let opts =
let opts = JsonSerializerOptions()
opts.WriteIndented <- true
opts
let json =
// serializamos el array con la libreria System.Text.Json que viene
// de manera predeterminada en el SDK de .NET
JsonSerializer.SerializeToUtf8Bytes(posts, opts)
printfn "Saving to \"./posts.json\""
// escribimos el archivo al disco
return! File.WriteAllBytesAsync("./posts.json", json)
}
Despues de esto pues el resultado lo aplicamos a la funcion Async.AwaitTask debido a que F# implementa la programacion asincrona de dos maneras, con Async y con Task siendo Task un tipo proveniente principalmente de C# mientras que Async fue el pionero de async/await en .NET al final como F# no tiene un a funcion main asincrona entonces esperamos a que se complete el trabajo asincrono y terinamos el programa con un codigo de salida 0
El resultado debe ser mas o menos esto
NOTA: ese gif tiene codigo viejo, pero el resultado es el mismo
Notas y Conclusiones
El proceso que realice para llegar a esta conclusion fue basicamente ir a mi blog con un navegador comun y corriente, inspeccionar elemento y analizar la estructura del sitio para determinar que clases y elementos son los que debia buscar, basado en eso pude tomar las decisiones sobre como trabajar con cada elemento.
F# es un lenguaje bastante conciso, la programacion paralela y asincrona podrian ser algunas de las mas complejas de mentalizar, pero quiero pensar que en la funcion getPostSummaries pudimos aplicar de hecho las dos de una manera en la que no genero una quemada mental y que fue relativamente sencillo de seguir.
Nos vemos en la siguiente entrada!
Is there something wrong? Raise an issue!
Or if it's simpler, find me in Threads!