Web Scrapping with F#
NOTA: The content of this post is based on this code, check it for the full example.
https://github.com/AngelMunoz/Escalin
Simple things in F#
Hey there, this is the next entry in Simple Things in F#
If you've ever wanted to pull data periodically from a website, or you are a QA automation person looking to do E2E (end to end) testing, then Playwright might be an option for you. Similar to Cypress or PhantomJS, Playwright is a library that allows you to automate ineractions with websites, you can even take screenshots and PDFs!
Playwright offers access to the following browsers
- Chromium
- Edge
- Chrome
- Firefox
- Webkit
Normally these tools are made with javascript in mind (playwright is no exception) but, Playwright offers .NET libraries as well so if you like to use F#, VB or even C#, you can do some web scrapping, E2E with playwright.
Pre-requisites
We will focus on F# here so you are required to have the .NET SDK installed on your machine, also you will need the playwright global cli tool (there's an npm version as well if you prefer to install that
dotnet tool install --global Microsoft.Playwright.CLI
Once installed we can create a new console project in the following way:
# feel free to use VB o C# if you prefer it
dotnet new console -lang F# -o Escalin
In this case I made a poject called Escalin, once created the project we'll install these dependencies.
cd Escalin
dotnet add package Microsoft.Playwright
dotnet add package Ply
dotnet build
# this is required in order to install the browsers playwright uses
# if you've installed them before (via npm or even the same tool)
# you can omit this step
playwright install
SCRIPTING: You can actually use playwright with F# scripts as well but you will need to install the playwright browsers first on that machine either by creating a dummy project and run the dotnet tool or using playwright npm tool to download them
Once we have our dependencies ready, we can start digging in with the code in VSCode using Ionide, Rider or Visual Studio.
Exercise
For today's exercise we will do a web scrapping of my own blog, and get a list of the post summaries in the index page and save them as a json file
To do that, we will need to do the following:
- Navigate to
https://blog.tunaxor.me - Select all of the post entries in the index page
- Extract all the text from each entry
- Generate a "Post" from each text block
- Write a JSON file called
posts.json
Let's start with the namespaces and a few types we will need to get our work done.
open Microsoft.Playwright
// Playwright is very heavy on task methods we'll need this
open System.Threading.Tasks
open FSharp.Control.Tasks
// This one is to write to disk
open System.IO
// Json serialization
open System.Text.Json
// Playwright offers different browsers so let's
// declare a Discrimiated union with our choices
type Browser =
| Chromium
| Chrome
| Edge
| Firefox
| Webkit
// let's also define a "pretty" representation of those
member instance.AsString =
match instance with
| Chromium -> "Chromium"
| Chrome -> "Chrome"
| Edge -> "Edge"
| Firefox -> "Firefox"
| Webkit -> "Webkit"
type Post =
{ title: string
author: string
summary: string
tags: string array
date: string }
Also, our main's goal is to have something like this:
[<EntryPoint>]
let main _ =
Playwright.CreateAsync()
|> getBrowser Firefox
|> getPage "https://blog.tunaxor.me"
|> getPostSummaries
|> writePostsToFile
|> Async.AwaitTask
|> Async.RunSynchronously
0
That means we will need to create the following functions
getBrowser- that takes both a browser and a Task with a playwright instancegetPage- that takes both a string (url) and a Task with a browser instancegetPostSummaries- that takes a Task with a page instanceWritePostsToFile- that takes a Task with a post array
in the case of Async.AwaitTask and Async.RunSynchronously it's not necessary since they are FSharp.Core implementations, we'll also use the pipe operator |> to apply the last's function result as a parameter for the next function.
The
pipeoperator is very useful in F# it could also make it to javascript at some pointif we want to visualize that in another way, we can think of it as this:
64 |> addNumbers 10is equivalent toaddNumbers 10 64
Let's get started with getBrowser
NOTE: I changed the parameters here vs the source code be more readable
let getBrowser (kind: Browser) (getPlaywright: Task<IPlaywright>) =
task {
// it's like we wrote
// let playwright = await getPlaywright
let! playwright = getPlaywright
printfn $"Browsing with {kind.AsString}"
/// return! is like `return await`
return!
match kind with
| Chromium -> pl.Chromium.LaunchAsync()
| Chrome ->
let opts = BrowserTypeLaunchOptions()
opts.Channel <- "chrome"
pl.Chromium.LaunchAsync(opts)
| Edge ->
let opts = BrowserTypeLaunchOptions()
opts.Channel <- "msedge"
pl.Chromium.LaunchAsync(opts)
| Firefox -> pl.Firefox.LaunchAsync()
| Webkit -> pl.Webkit.LaunchAsync()
}
In this case, we're not doing much rather than just creating a browser instance and returning it, think about it as a simple helper function that you can also modify to pass in browser options and other things if you need them further down the line.
We are also taking the task as the parameter, so we can use the pipe operator easily the downside here I guess is that we have to do let! playwright = getPlaywright but I don't think too much about it, the benefit is that we can make our main function more legible and gives us a clear indication of how we want to proceed.
The next is getPage
let getPage (url: string) (getBrowser: Task<IBrowser>) =
task {
let! browser = getBrowser
printfn $"Navigating to \"{url}\""
// we'll get a new page first
let! page = browser.NewPageAsync()
// let's navigate right into the url
let! res = page.GotoAsync url
// we will ensure that we navigated successfully
if not res.Ok then
// we could use a result here to better handle errors, but
// for simplicity we'll just fail of we couldn't navigate correctly
return failwith "We couldn't navigate to that page"
return page
}
This function is also short, we just open a new page and go yo a particular URL and ensure we did it correctly, once we're done that we just return the page
The next function is getPostSummaries that will find all of the post summaries in the page we just visited on the last function.
let getPostSummaries (getPage: Task<IPage>) =
task {
let! page = getPage
// The first scrapping part, we'll get all of the elements that have
// the "card-content" class
let! cards = page.QuerySelectorAllAsync(".card-content")
printfn $"Getting Cards from the landing page: {cards.Count}"
return!
cards
// we'll convert the readonly list to an array
|> Seq.toArray
// we'll use the `Parallel` module to precisely process each post
// in parallel and apply the `convertElementToPost` function
|> Array.Parallel.map convertElementToPost
// at this point we have a Task<Post>[]
// so we'll pass it to the next function to ensure all of the tasks
// are resolved
|> Task.WhenAll // return a Task<Post[]>
}
Before we get to the next one, we need to check what is convertElementToPost doing, how did we go from an element read only list to a post array? let's make a list of things we need to do in order to get a post so the code doesn't look too alien
- Inside of the element, search for the title
- Inside of the element, search for the author
- Inside of the element, search for the content
- Extract the text from the title and the author
- The content will be split in an array where the text has
... - For the summary we'll get the first element of the array or return an empty string
- The second element will be divided where we have the
\ncharacter- To the first element of that array, we'll divide it as well where we have a
#to get our tags. - Trim the strings from extra spaces and filter out empty strings
- The second element will get trimmed from spaces as well and that will be our date
- To the first element of that array, we'll divide it as well where we have a
All of this, based on knowing that the content might come like this
Simple things in F If you come from PHP, Javascript this might help you understand a... #dotnet #fsharp #mvc #saturn \nJul 16, 2021
let convertElementToPost (element: IElementHandle) =
task {
// steps 1, 2 y 3
let! headerContent = element.QuerySelectorAsync(".title")
let! author = element.QuerySelectorAsync(".subtitle a")
let! content = element.QuerySelectorAsync(".content")
// step 4
let! title = headerContent.InnerTextAsync()
let! authorText = author.InnerTextAsync()
let! rawContent = content.InnerTextAsync()
// step 5
let summaryParts = rawContent.Split("...")
let summary =
// step 6
summaryParts
|> Array.tryHead
|> Option.defaultValue ""
// try to split the tags and the date
let extraParts =
// step 7
(summaryParts
|> Array.tryLast
// we'll default to a single character string to ensure we will have
// at least an array with two elements ["", ""]
|> Option.defaultValue "\n")
.Split '\n'
// split the tags given that each has a '#' and trim it, remove it if it's whitespace
let tags =
// step 7.1
(extraParts
|> Array.tryHead
|> Option.defaultValue "")
.Split('#')
// step 7.2
|> Array.map (fun s -> s.Trim())
|> Array.filter (System.String.IsNullOrWhiteSpace >> not)
let date =
// step 7.3
extraParts
|> Array.tryLast
|> Option.defaultValue ""
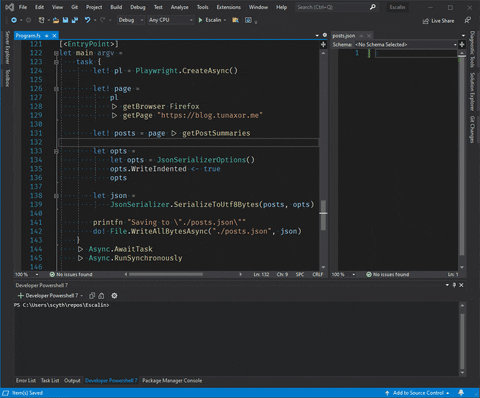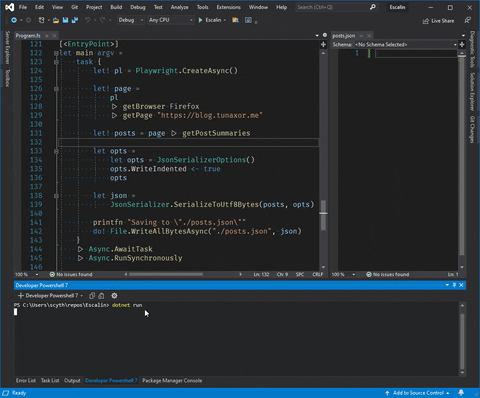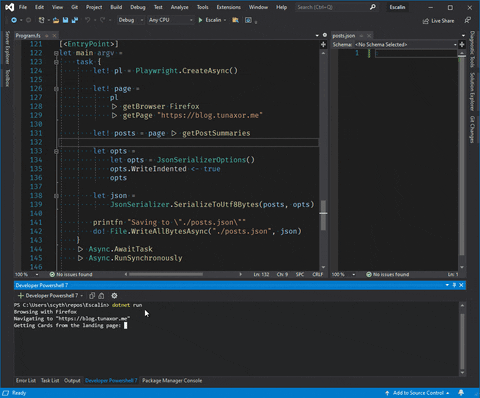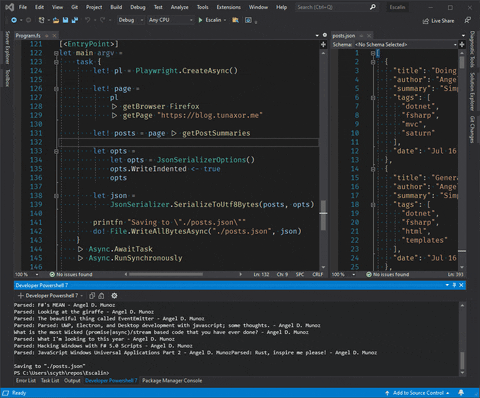
printfn $"Parsed: {title} - {authorText}"
// return el post
return
{ title = title
author = authorText
tags = tags
summary = $"{summary}..."
date = date }
}
Phew! that was intense right? string handling is a mess specially if I'm around, that's what my mind could produce but hey as long as it works! the other web scrapping thing we did here was at the beggining, once we knew we were inside a card, we could safely query elements and know they were going to be only children of that card after we processed the text we're ready to go.
Let's get to the last step in our main writePostsToFile, this will just take the post array task we returned on the last function chain and then just write that to the disk.
let writePostsToFile (getPosts: Task<Post array>) =
task {
let! posts = getPosts
let opts =
let opts = JsonSerializerOptions()
opts.WriteIndented <- true
opts
let json =
// serialize the array with the base class library System.Text.Json
JsonSerializer.SerializeToUtf8Bytes(posts, opts)
printfn "Saving to \"./posts.json\""
// write those bytes to dosk
return! File.WriteAllBytesAsync("./posts.json", json)
}
Once we're done with all of that we just apply the result to Async.AwaitTask given that F#'s Async/Task aren't the same,
F# doesn't really have an async main so that's why we run that last task synchronously and return 0 at the end
The result should look like this
NOTE: that gif contains old code but produces the same output
Notes and Conclusions
The process I went through to get to this code was basically to go to my blog, inspect it with my browser and start analyzing the website's structure, once I kind of knew what was the ideal path to do it and what where the classes/elements I needed to look for I started with the web scrapping part.
Keep in mind that playwright has many many options, you can perform clicks, text inputs get screenshots, pdfs, do mouse events and a lot of things that can help you archieve your goals either by doing Testing or doing some web scrapping as I just showed you.
F# is a pretty concise language, and just think about if for a minute, async and parallel programing could be some of the most complex to mentalize yet we just did both and even mixed them in a way that really felt natural or at least I hope it felt that way for you as well isn't that amazing?
have fun and I will see you again in the next entry!
Is there something wrong? Raise an issue!
Or if it's simpler, find me in Threads!